|
I am a PhD student in the Computer Vision group at MPI Informatics in Saarbrücken, supervised by Prof. Bernt Schiele. I was a research intern at Samsung AI Cambridge during the summer of 2025, where I worked on multimodal large language models. Prior to that, I was part of the preparatory phase of the Saarbrücken Graduate School of Computer Science. I completed my bachelor’s degree in Information Technology at IIIT Allahabad (2013–2017). My recent interests include reasoning with multimodal LLMs and improving their efficiency. Email / CV / Google Scholar / Twitter / Github |

|
|
|
|
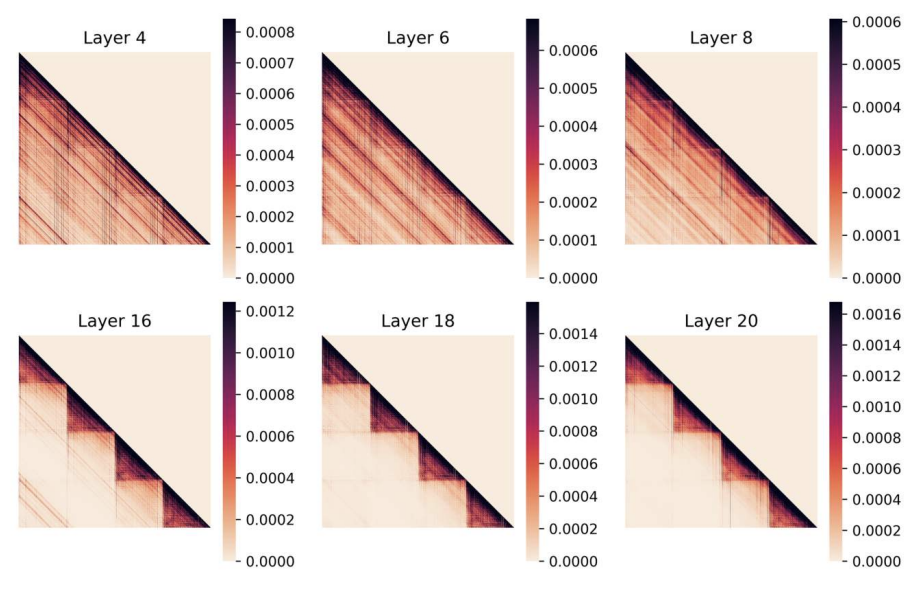
Anurag Das, Adrian Bulat, Alberto Baldrati, Ioannis Metaxas, Bernt Schiele Georgios Tzimiropoulos, Brais Martinez ACL Findings, 2026 Although Large Vision–Language Models (LVLMs) excel on many tasks, their ability to reason over multiple images is poorly understood and insufficiently analyzed. We introduce MIMIC, a diagnostic benchmark that exposes fundamental multi-image failures in LVLMs and propose complementary data-generation and attention-masking remedies that significantly improve cross-image reasoning and achieve state-of-the-art performance on multi-image benchmarks. |
|
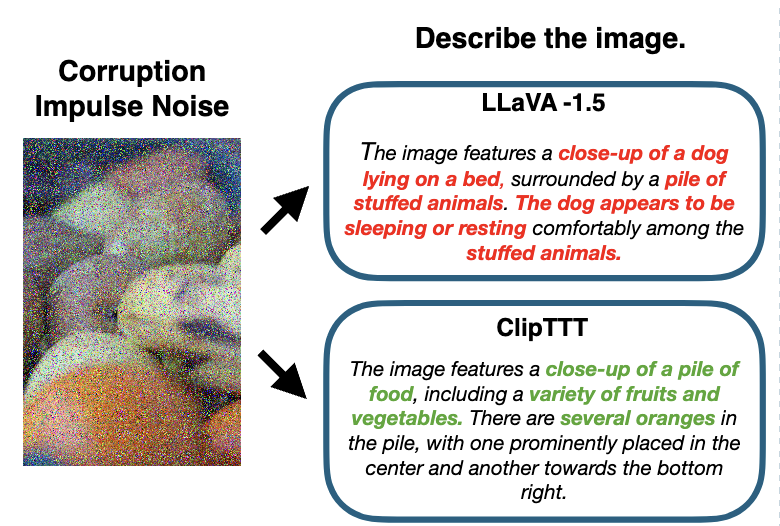
Mriganka Nath*, Anurag Das*, Jiahao Xie, Bernt Schiele arxiv, 2026 ClipTTT reduces hallucinations in large vision-language models when corrupted test images cause distribution shift and unreliable generation. It uses CLIP-guided test-time adaptation on a single sample to improve faithfulness under 15 common corruptions without modifying the base LVLM. |
|
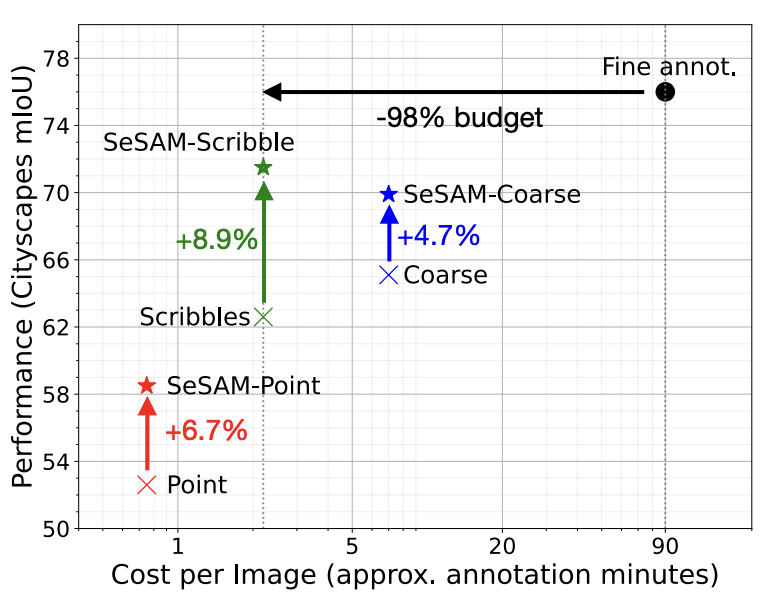
Anurag Das*, Anna Kukleva, Xinting Hu, Yuki Asano, Bernt Schiele arxiv, 2026 SeSAM enables semantic segmentation with weak annotations by adapting SAM through instance decomposition, skeleton-based point prompts, mask selection, and iterative pseudo-label refinement. Combined with semi-supervised learning, it improves segmentation performance across benchmarks while greatly reducing annotation cost compared with dense pixel-level supervision. |
|
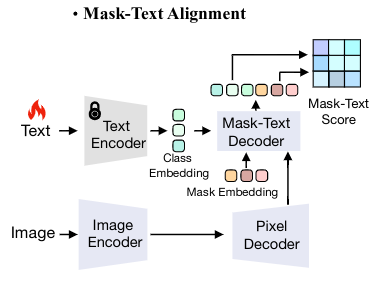
Anurag Das, Xinting Hu, Li Jiang, Bernt Schiele ECCV, 2024 We propose mask-text alignment based framework for improved semantic segmentation result. We show how mask-text alignment is better than pixel-text alignment for dense semantic segmentation task. |

|
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, Jan Eric Lenssen ECCV, 2024 We propose a 3D-aware finetuning of 2D foundational models, resulting in improved performance on downstream tasks such as semantic segmentation and depth estimation. |
|
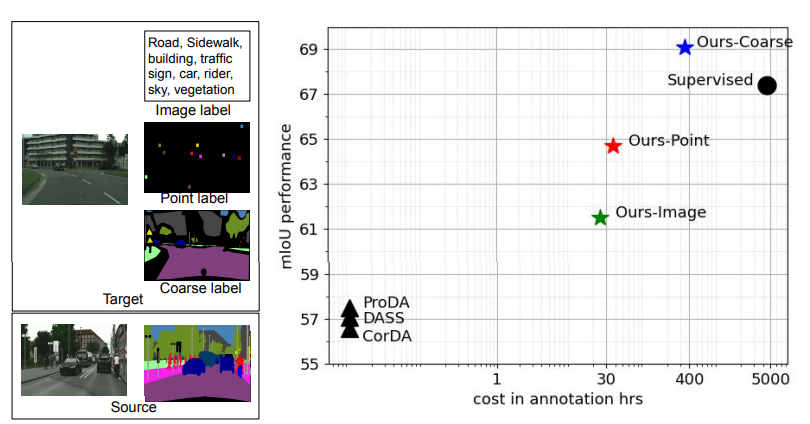
Anurag Das, Yongqin Xian, Dengxin Dai, Bernt Schiele CVPR, 2023 We propose a common framework to use different weak labels, e.g., image, point and coarse labels from the target domain to reduce the performance gap between UDA and supervised learning. |
|
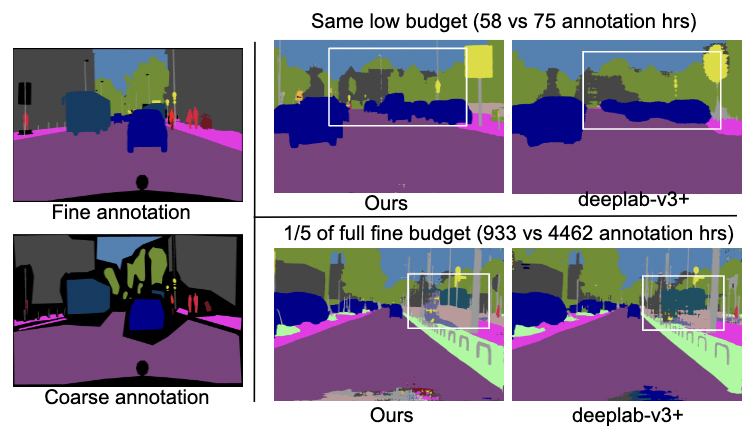
Anurag Das, Yongqin Xian, Yang He, Zeynep Akata, Bernt Schiele WACV, 2023 We propose to utlize cheaper coarse annotations for urban scene semantic segmentation. Coarse annotation lacks fine Boundary details and are faster to annotate. Our proposed method obtains competitive performance with coarse annotation along with relatively free synthetic data compared with fine annotation at a fraction of the annotation budget. |
|
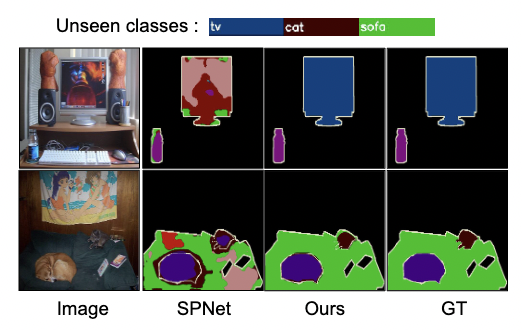
Anurag Das, Yongqin Xian, Yang He, Zeynep Akata, Bernt Schiele GCPR, 2021 [ Best Master Thesis Award in Germany] Generalized Zero-shot Semantic Segmentation(GZSS) is a challenging problem as the prior works don't generalize well on unseen classes. we propose to leverage a class-agnostic segmentation prior provided by superpixels and introduce a superpixel pooling (SP-pooling) module that improves the performance on GZSS task. |
|
|
| Master Thesis |
Saarland University, 2021 |
|
|
|
|
|
|